
冯大仙
CVPR导读
一种轻量化的讲话人检测模型
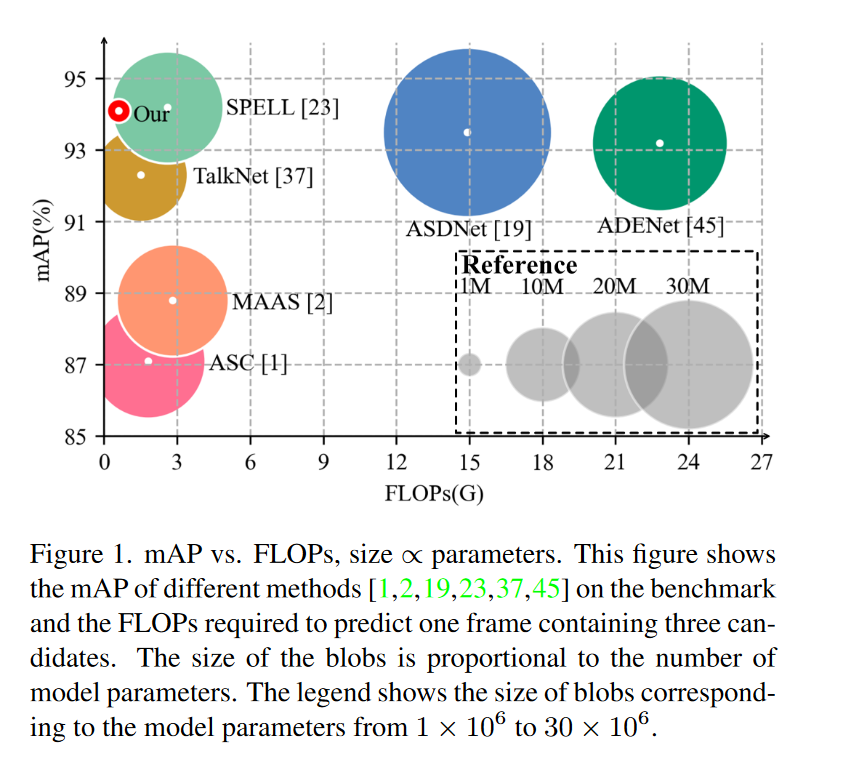
原文:A Light Weight Model for Active Speaker Detection什么是讲话人检测(active speaker detection) ASD任务是实现在任意视频中从一群候选者中找到正在说话的人,该任务是一种多模态任务,其输入为视频和声音信号。故可以归类为音频-视频任务。当前比较有名的大数据集是AVA-ActiveSpeaker。目前主流的方法为,将一系列候选者的人脸序列输入到3D卷积神经网络中提取特征,再通过复杂的注意力模块建模跨模态信息。这类方法的缺点是内存消耗大,计算负担大。这大大限制了在实时场景下的应用。Let's go! 进入正文本...



最近评论